
The first post in this series made it clear that the major computational and storage costs to implementing the Gauss-Newton algorithm come in computing the matrices 
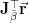
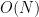

In this post we will see how to eliminate that requirement and perform the Gauss-Newton algorithm in a one-pass streaming algorithm with space complexity effectively 
1. The heart of the matter
Notice that we can rewrite the 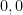
![\displaystyle \begin{array}{rcl} [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{00} &=& \sum_{i=0}^{N-1} 4\frac{(x_{i0} - \beta_{0})^2}{\beta_{3}^4} \\ &=& \frac{4}{\beta_{3}^4}\left[ \sum_{i=0}^{N-1} x_{i0}^2 - 2\beta_0\sum_{i=0}^{N-1}x_{i0} + \sum_{i=0}^{N-1}\beta_0^2\right] \\ &=& \frac{4}{\beta_3^4}\sum_{i=0}^{N-1}x_{i0}^2 - \frac{8\beta_0}{\beta_3^4}\sum_{i=0}^{N-1}x_{i0} + \frac{4\beta_0^2}{\beta_3^4}N \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7B00%7D+%26%3D%26+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bi0%7D+-+%5Cbeta_%7B0%7D%29%5E2%7D%7B%5Cbeta_%7B3%7D%5E4%7D+%5C%5C+%26%3D%26+%5Cfrac%7B4%7D%7B%5Cbeta_%7B3%7D%5E4%7D%5Cleft%5B+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+x_%7Bi0%7D%5E2+-+2%5Cbeta_0%5Csum_%7Bi%3D0%7D%5E%7BN-1%7Dx_%7Bi0%7D+%2B+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D%5Cbeta_0%5E2%5Cright%5D+%5C%5C+%26%3D%26+%5Cfrac%7B4%7D%7B%5Cbeta_3%5E4%7D%5Csum_%7Bi%3D0%7D%5E%7BN-1%7Dx_%7Bi0%7D%5E2+-+%5Cfrac%7B8%5Cbeta_0%7D%7B%5Cbeta_3%5E4%7D%5Csum_%7Bi%3D0%7D%5E%7BN-1%7Dx_%7Bi0%7D+%2B+%5Cfrac%7B4%5Cbeta_0%5E2%7D%7B%5Cbeta_3%5E4%7DN+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
So if we know 
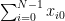

A similar situation arises for all og the matrix entries. Before proceeding, let’s introduce some new notation that will make the sequel easier to follow, easier to code, and easier to generalize.
2. Notation
To think clearly about the calculations here, we need to stop thinking about 3-vectors and start thinking about 
![\displaystyle \vec{\mathbf{x}}_{\bullet j} = \left[ \begin{array}{c} x_{0j} \\ x_{1j} \\ \vdots \\ x_{(N-1)j}\end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x_%7B0j%7D+%5C%5C+x_%7B1j%7D+%5C%5C+%5Cvdots+%5C%5C+x_%7B%28N-1%29j%7D%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
This is the
![\displaystyle \vec{\mathbf{x^2}}_{\bullet j} = \left[ \begin{array}{c} x_{0j}^2 \\ x_{1j}^2 \\ \vdots \\ x_{(N-1)j}^2\end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+j%7D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x_%7B0j%7D%5E2+%5C%5C+x_%7B1j%7D%5E2+%5C%5C+%5Cvdots+%5C%5C+x_%7B%28N-1%29j%7D%5E2%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
This is the
![\displaystyle \vec{\mathbf{1}} = \left[ \begin{array}{c}1 \\ 1 \\ \vdots \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D1+%5C%5C+1+%5C%5C+%5Cvdots+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
For any pair of 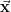
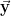

With this notation, we can rewrite the formula in the last section as
![\displaystyle \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{00} = \frac{4}{\beta_3^4}\left( \langle \vec{\mathbf{x}}_{\bullet 0}, \vec{\mathbf{x}}_{\bullet 0} \rangle - 2\beta_0\langle \vec{\mathbf{x}}_{\bullet 0}, \vec{\mathbf{1}} \rangle +\beta_0^2 N\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7B00%7D+%3D+%5Cfrac%7B4%7D%7B%5Cbeta_3%5E4%7D%5Cleft%28+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+0%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+0%7D+%5Crangle+-+2%5Cbeta_0%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+0%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+%2B%5Cbeta_0%5E2+N%5Cright%29+&bg=ffffff&fg=000000&s=0&c=20201002)
3. Rewriting the matrix entry formulas
We will rewrite each of the formulas derived in post 2 in terms of these
For

![\displaystyle \begin{array}{rcl} \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{jk} &=& \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{kj} = \sum_{i=0}^{N-1} 4\frac{(x_{ij} - \beta_{j})(x_{ik} - \beta_{k})}{\beta_{3+j}^2\beta_{3+k}^2} \\ &=& \frac{4}{\beta_{3+j}^2\beta_{3+k}^2}\left( \langle \vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{x}}_{\bullet k} \rangle - \beta_j\langle \vec{\mathbf{x}}_{\bullet k}, \vec{\mathbf{1}} \rangle - \beta_k \langle\vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{1}} \rangle + \beta_j\beta_k N \right) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bjk%7D+%26%3D%26+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bkj%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bij%7D+-+%5Cbeta_%7Bj%7D%29%28x_%7Bik%7D+-+%5Cbeta_%7Bk%7D%29%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%5Cbeta_%7B3%2Bk%7D%5E2%7D+%5C%5C+%26%3D%26+%5Cfrac%7B4%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%5Cbeta_%7B3%2Bk%7D%5E2%7D%5Cleft%28+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+-+%5Cbeta_j%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+-+%5Cbeta_k+%5Clangle%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+%2B+%5Cbeta_j%5Cbeta_k+N+%5Cright%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
for
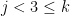
![\displaystyle \begin{array}{rcl} \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{jk} &=& \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{kj} \\ &=& \sum_{i=0}^{N-1} 4\frac{(x_{ij} - \beta_{j})(x_{i(k-3)} - \beta_{(k-3)})^2}{\beta_{3+j}^2\beta_{k}^3} \\ &=& \frac{4}{\beta_{3+j}^2\beta_{k}^3}\left( \langle \vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{x^2}}_{\bullet (k-3)} \rangle -2 \beta_{(k-3)}\langle \vec{\mathbf{x}}_{\bullet j},\vec{\mathbf{x}}_{\bullet (k-3)} \rangle + \beta_{(k-3)}^2 \langle\vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{1}} \rangle \right. \\ & & \left. \qquad - \beta_j\langle \vec{\mathbf{x}}_{\bullet (k-3)}, \vec{\mathbf{x}}_{\bullet (k-3)}\rangle + 2\beta_j\beta_{(k-3)}\langle \vec{\mathbf{x}}_{\bullet (k-3)}, \vec{\mathbf{1}}\rangle - \beta_j\beta_{(k-3)}^2 N \right) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bjk%7D+%26%3D%26+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bkj%7D+%5C%5C+%26%3D%26+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bij%7D+-+%5Cbeta_%7Bj%7D%29%28x_%7Bi%28k-3%29%7D+-+%5Cbeta_%7B%28k-3%29%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%5Cbeta_%7Bk%7D%5E3%7D+%5C%5C+%26%3D%26+%5Cfrac%7B4%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%5Cbeta_%7Bk%7D%5E3%7D%5Cleft%28+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+-2+%5Cbeta_%7B%28k-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+%2B+%5Cbeta_%7B%28k-3%29%7D%5E2+%5Clangle%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+%5Cright.+%5C%5C+%26+%26+%5Cleft.+%5Cqquad+-+%5Cbeta_j%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D%5Crangle+%2B+2%5Cbeta_j%5Cbeta_%7B%28k-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D%5Crangle+-+%5Cbeta_j%5Cbeta_%7B%28k-3%29%7D%5E2+N+%5Cright%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and for
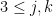
![\displaystyle \begin{array}{rcl} \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{jk} &=& \left[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}\right]_{kj} \\ &=& \sum_{i=0}^{N-1} 4\frac{(x_{i(j-3)} - \beta_{(j-3)})^2(x_{i(k-3)} - \beta_{(k-3)})^2}{\beta_{j}^3\beta_{k}^3} \\ &=& \frac{4}{\beta_{j}^3\beta_{k}^3}\left( \langle \vec{\mathbf{x^2}}_{\bullet ( j-3)}, \vec{\mathbf{x^2}}_{\bullet (k-3)} \rangle -2 \beta_{(k-3)}\langle \vec{\mathbf{x^2}}_{\bullet (j-3)},\vec{\mathbf{x}}_{\bullet (k-3)} \rangle \right. \\ && \qquad+ \beta_{(k-3)}^2 \langle\vec{\mathbf{x^2}}_{\bullet (j-3)}, \vec{\mathbf{1}} \rangle -2\beta_{(j-3)}\langle \vec{\mathbf{x}}_{\bullet (j-3)}, \vec{\mathbf{x^2}}_{\bullet (k-3)} \rangle \\ & & \qquad + 4\beta_{(j-3)}\beta_{(k-3)}\langle \vec{\mathbf{x}}_{\bullet (j -3)},\vec{\mathbf{x}}_{\bullet (k-3)} \rangle - 2\beta_{(j-3)}\beta_{(k-3)}^2 \langle \vec{\mathbf{x}}_{\bullet (j-3)}, \vec{\mathbf{1}}\rangle \\ & & \left. \qquad + \beta_{(j-3)}^2 \langle\vec{\mathbf{1}}, \vec{\mathbf{x^2}}_{\bullet (k-3)} \rangle - 2\beta_{(j-3)}^2\beta_{(k-3)}\langle \vec{\mathbf{1}}, \vec{\mathbf{x}}_{\bullet (k-3)}\rangle - \beta_{(j-3)}^2\beta_{(k-3)}^2 N \right) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bjk%7D+%26%3D%26+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bkj%7D+%5C%5C+%26%3D%26+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bi%28j-3%29%7D+-+%5Cbeta_%7B%28j-3%29%7D%29%5E2%28x_%7Bi%28k-3%29%7D+-+%5Cbeta_%7B%28k-3%29%7D%29%5E2%7D%7B%5Cbeta_%7Bj%7D%5E3%5Cbeta_%7Bk%7D%5E3%7D+%5C%5C+%26%3D%26+%5Cfrac%7B4%7D%7B%5Cbeta_%7Bj%7D%5E3%5Cbeta_%7Bk%7D%5E3%7D%5Cleft%28+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28+j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+-2+%5Cbeta_%7B%28k-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+%5Cright.+%5C%5C+%26%26+%5Cqquad%2B+%5Cbeta_%7B%28k-3%29%7D%5E2+%5Clangle%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+-2%5Cbeta_%7B%28j-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+%5C%5C+%26+%26+%5Cqquad+%2B+4%5Cbeta_%7B%28j-3%29%7D%5Cbeta_%7B%28k-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j+-3%29%7D%2C%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+-+2%5Cbeta_%7B%28j-3%29%7D%5Cbeta_%7B%28k-3%29%7D%5E2+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D%5Crangle+%5C%5C+%26+%26+%5Cleft.+%5Cqquad+%2B+%5Cbeta_%7B%28j-3%29%7D%5E2+%5Clangle%5Cvec%7B%5Cmathbf%7B1%7D%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28k-3%29%7D+%5Crangle+-+2%5Cbeta_%7B%28j-3%29%7D%5E2%5Cbeta_%7B%28k-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7B1%7D%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28k-3%29%7D%5Crangle+-+%5Cbeta_%7B%28j-3%29%7D%5E2%5Cbeta_%7B%28k-3%29%7D%5E2+N+%5Cright%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
To we write similar expressions for the entries of

So for

![\displaystyle \begin{array}{rcl} \left[\mathbf{J}_{\bar{\beta}}^{\top}\vec{\mathbf{r}}\right]_{j} &=& \sum_{i=0}^{N-1}2\frac{x_{ij} - \beta_{j}}{\beta_{3+j}^2} \left( 1 - \sum_{k=0,1,2} \frac{(x_{ik} - \beta_{k})^2}{\beta_{3+k}^2} \right) \\ &=& \frac{2}{\beta_{3+j}^2} \left(\langle \vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{1}} \rangle - \sum_{k=1,2,3} \left(\langle \vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{x^2}}_{\bullet k} \rangle - 2\beta_k\langle \vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{x}}_{\bullet k} \rangle + \beta_k^2 \langle \vec{\mathbf{x}}_{\bullet j}, \vec{\mathbf{1}} \rangle\right) \right. \\ && \qquad \left. - \beta_j N + \beta_j\sum_{k=1,2,3} \left(\langle \vec{\mathbf{1}}, \vec{\mathbf{x^2}}_{\bullet k} \rangle - 2\beta_k\langle \vec{\mathbf{1}}, \vec{\mathbf{x}}_{\bullet k} \rangle + \beta_k^2 N\right) \right) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cvec%7B%5Cmathbf%7Br%7D%7D%5Cright%5D_%7Bj%7D+%26%3D%26+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D2%5Cfrac%7Bx_%7Bij%7D+-+%5Cbeta_%7Bj%7D%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%7D+%5Cleft%28+1+-+%5Csum_%7Bk%3D0%2C1%2C2%7D+%5Cfrac%7B%28x_%7Bik%7D+-+%5Cbeta_%7Bk%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bk%7D%5E2%7D+%5Cright%29+%5C%5C+%26%3D%26+%5Cfrac%7B2%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+-+%5Csum_%7Bk%3D1%2C2%2C3%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+-+2%5Cbeta_k%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+%2B+%5Cbeta_k%5E2+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+j%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle%5Cright%29+%5Cright.+%5C%5C+%26%26+%5Cqquad+%5Cleft.+-+%5Cbeta_j+N+%2B+%5Cbeta_j%5Csum_%7Bk%3D1%2C2%2C3%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7B1%7D%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+-+2%5Cbeta_k%5Clangle+%5Cvec%7B%5Cmathbf%7B1%7D%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+%2B+%5Cbeta_k%5E2+N%5Cright%29+%5Cright%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and for
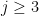
![\displaystyle \begin{array}{rcl} \left[\mathbf{J}_{\bar{\beta}}^{\top}\vec{\mathbf{r}}\right]_{j} &=& \sum_{i=0}^{N-1}2\frac{(x_{i(j-3)} - \beta_{j-3})^2}{\beta_{j}^3} \left( 1 - \sum_{k=0,1,2} \frac{(x_{ik} - \beta_{k})^2}{\beta_{3+k}^2} \right) \\ &=& \frac{2}{\beta_{j}^3} \left(\langle \vec{\mathbf{x^2}}_{\bullet (j-3)}, \vec{\mathbf{1}} \rangle - \sum_{k=1,2,3} \left(\langle \vec{\mathbf{x^2}}_{\bullet (j -3)}, \vec{\mathbf{x^2}}_{\bullet k} \rangle - 2\beta_k\langle \vec{\mathbf{x^2}}_{\bullet (j-3)}, \vec{\mathbf{x}}_{\bullet k} \rangle + \beta_k^2 \langle \vec{\mathbf{x^2}}_{\bullet (j-3)}, \vec{\mathbf{1}} \rangle\right) \right. \\ && \qquad -2\beta_{(j-3)}\langle \vec{\mathbf{x}}_{\bullet (j-3)}, \vec{\mathbf{1}} \rangle + 2\beta_{(j-3)} \sum_{k=1,2,3} \left(\langle \vec{\mathbf{x}}_{\bullet (j-3)}, \vec{\mathbf{x^2}}_{\bullet k} \rangle - 2\beta_k\langle \vec{\mathbf{x}}_{\bullet (j-3)}, \vec{\mathbf{x}}_{\bullet k} \rangle + \beta_k^2 \langle \vec{\mathbf{x}}_{\bullet (j-3)}, \vec{\mathbf{1}} \rangle\right) \\ && \qquad \left. + \beta_{(j-3)}^2 N - \beta_{(j-3)}^2\sum_{k=1,2,3} \left(\langle \vec{\mathbf{1}}, \vec{\mathbf{x^2}}_{\bullet k} \rangle - 2\beta_k\langle \vec{\mathbf{1}}, \vec{\mathbf{x}}_{\bullet k} \rangle + \beta_k^2 N\right) \right) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cvec%7B%5Cmathbf%7Br%7D%7D%5Cright%5D_%7Bj%7D+%26%3D%26+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D2%5Cfrac%7B%28x_%7Bi%28j-3%29%7D+-+%5Cbeta_%7Bj-3%7D%29%5E2%7D%7B%5Cbeta_%7Bj%7D%5E3%7D+%5Cleft%28+1+-+%5Csum_%7Bk%3D0%2C1%2C2%7D+%5Cfrac%7B%28x_%7Bik%7D+-+%5Cbeta_%7Bk%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bk%7D%5E2%7D+%5Cright%29+%5C%5C+%26%3D%26+%5Cfrac%7B2%7D%7B%5Cbeta_%7Bj%7D%5E3%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+-+%5Csum_%7Bk%3D1%2C2%2C3%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28j+-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+-+2%5Cbeta_k%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+%2B+%5Cbeta_k%5E2+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle%5Cright%29+%5Cright.+%5C%5C+%26%26+%5Cqquad+-2%5Cbeta_%7B%28j-3%29%7D%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle+%2B+2%5Cbeta_%7B%28j-3%29%7D+%5Csum_%7Bk%3D1%2C2%2C3%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+-+2%5Cbeta_k%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+%2B+%5Cbeta_k%5E2+%5Clangle+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+%28j-3%29%7D%2C+%5Cvec%7B%5Cmathbf%7B1%7D%7D+%5Crangle%5Cright%29+%5C%5C+%26%26+%5Cqquad+%5Cleft.+%2B+%5Cbeta_%7B%28j-3%29%7D%5E2+N+-+%5Cbeta_%7B%28j-3%29%7D%5E2%5Csum_%7Bk%3D1%2C2%2C3%7D+%5Cleft%28%5Clangle+%5Cvec%7B%5Cmathbf%7B1%7D%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%5E2%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+-+2%5Cbeta_k%5Clangle+%5Cvec%7B%5Cmathbf%7B1%7D%7D%2C+%5Cvec%7B%5Cmathbf%7Bx%7D%7D_%7B%5Cbullet+k%7D+%5Crangle+%2B+%5Cbeta_k%5E2+N%5Cright%29+%5Cright%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
These expressions may look tedious, but they are just straightforward algebra. If we scan the observation data 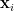

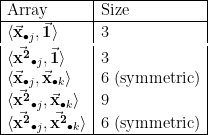
In fact, the situation is even better. Notice that

So we do not need to store 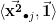

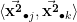
4. Putting it into code
Implementing this is straightforward even if it demands a bit of care. To see this implemented, look at the file BestSphereGaussNewtonCalibrator.cpp in muCSense. Here is a quick overview of what to look for.
- The arrays of statistics are private members of the
BestSphereGaussNewtonCalibratorclass and are declared in BestSphereGaussNewtonCalibrator.h
- The statistics are all accumulated in the function in the method
BestSphereGaussNewtonCalibrator::update(BestSphereGaussNewtonCalibrator.cpp). - The calibration matrices are computed in the function in the method
BestSphereGaussNewtonCalibrator::computeGNMatrices(BestSphereGaussNewtonCalibrator.cpp).In muCSense this sphere fitting procedure is used to calibrate “spherical sensors” such as magnetometers and accelerometers. At present, the library specifically supports the inertial sensors on SparkFun’s 9DoF Sensor Stick: the ADXL 345 accelerometer, HMC 5843 magnetometer, and the ITG 3200 gyroscope. To use this code to calibrate a different accelerometer or magnetometer, you just need to define a new subclass of Sensor — see ADXL345.h/ADXL345.cpp for an example — then follow this example sketch.
5. What’s next.
The code in muCSense works, but needs to be optimized. As it is, a simple sketch using this calibration algorithm takes up 20K of the 32K available on an Arduino Uno. The sums and products have a clear structure that I have not attempted to exploit at all. Using this structure should allow a valuable reduction in compiled code size. I will work on this, but would love to hear from anyone else who has some ideas.
It is interesting to note that this algorithm has a clear generalization to any residual function which is a polynomial of the observation vector. It works for higher dimensional observations and for higher degree polynomials. In particular, it can be adapted to handle linear maps with shear, something I plan to implement soon. The process I walked through here should be abstracted to build a system that takes a polynomial residual function as input and determines the statistics and computations needed in the background, optimizing the tedious arithmetic and saving us from writing this sort of code.
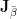 , the vector
, the vector 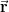 , and the set of observations
, and the set of observations 

