
I sketched a naïve implementation of the Gauss-Newton algorithm for sphere fitting, and provided an implementation in Octave. While it works fine on a laptop, it uses far too much memory to handle more than a handful of calibration samples on a microcontroller.
What took up all of that memory? The matrix 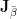
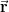
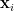
It turns out that we don’t really need to keep any of these around. In this post I’ll describe how to implement the algorithm without materializing
In the next post, I’ll show how to accumulate 25 statistics about the observations that have all of the information we need to run Gauss-Newton in constant space and time.
Let’s start by getting rid of the big arrays of statistics.
1. Only materialize what you need
When carrying out the Gauss-Newton algorithm as it was sketched in the last post, we never need direct access to the matrix entries of 
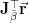
We will materialize these matrices instead of the big matrices.
This is possible because each matrix entry in
Let’s make this more concrete and look at the 00 entry of
![\displaystyle \left[\mathbf{J}_{\bar{\beta}}\right]_{ij} = \left\{ \begin{array}{ll} 2\frac{x_{ij} - \beta_{j}}{\beta_{3+j}^2} & 0 \leq j < 3;\\ 2\frac{(x_{ij} - \beta_{j})^2}{\beta_{3+j}^3} & 3 \leq j < 6.\end{array} \right.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5Cright%5D_%7Bij%7D+%3D+%5Cleft%5C%7B+%5Cbegin%7Barray%7D%7Bll%7D+2%5Cfrac%7Bx_%7Bij%7D+-+%5Cbeta_%7Bj%7D%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%7D+%26+0+%5Cleq+j+%3C+3%3B%5C%5C+2%5Cfrac%7B%28x_%7Bij%7D+-+%5Cbeta_%7Bj%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bj%7D%5E3%7D+%26+3+%5Cleq+j+%3C+6.%5Cend%7Barray%7D+%5Cright.+&bg=ffffff&fg=000000&s=0&c=20201002)
from which the definition of matrix multiplication gives
![\displaystyle [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{00} = \sum_{i=0}^{N-1} 4\frac{(x_{i0} - \beta_{0})^2}{\beta_{3}^4}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7B00%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bi0%7D+-+%5Cbeta_%7B0%7D%29%5E2%7D%7B%5Cbeta_%7B3%7D%5E4%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
So to compute ![{[\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{00}}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7B00%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The general matrix entries are as follows. For 
![\displaystyle [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{jk} = [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{kj} = \sum_{i=0}^{N-1} 4\frac{(x_{ij} - \beta_{j})(x_{ik} - \beta_{k})}{\beta_{3+j}^2\beta_{3+k}^2} \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7Bjk%7D+%3D+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7Bkj%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bij%7D+-+%5Cbeta_%7Bj%7D%29%28x_%7Bik%7D+-+%5Cbeta_%7Bk%7D%29%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%5Cbeta_%7B3%2Bk%7D%5E2%7D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
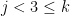
![\displaystyle [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{jk} = [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{kj} = \sum_{i=0}^{N-1} 4\frac{(x_{ij} - \beta_{j})(x_{i(k-3)} - \beta_{(k-3)})^2}{\beta_{3+j}^2\beta_{k}^3} \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7Bjk%7D+%3D+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7Bkj%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bij%7D+-+%5Cbeta_%7Bj%7D%29%28x_%7Bi%28k-3%29%7D+-+%5Cbeta_%7B%28k-3%29%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%5Cbeta_%7Bk%7D%5E3%7D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
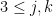
![\displaystyle [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{jk} = [\mathbf{J}_{\bar{\beta}}^{\top}\mathbf{J}_{\bar{\beta}}]_{kj} = \sum_{i=0}^{N-1} 4\frac{(x_{i(j-3)} - \beta_{(j-3)})^2(x_{i(k-3)} - \beta_{(k-3)})^2}{\beta_{j}^3\beta_{k}^3} \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7Bjk%7D+%3D+%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5D_%7Bkj%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D+4%5Cfrac%7B%28x_%7Bi%28j-3%29%7D+-+%5Cbeta_%7B%28j-3%29%7D%29%5E2%28x_%7Bi%28k-3%29%7D+-+%5Cbeta_%7B%28k-3%29%7D%29%5E2%7D%7B%5Cbeta_%7Bj%7D%5E3%5Cbeta_%7Bk%7D%5E3%7D+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)


![\displaystyle \left[\mathbf{J}_{\bar{\beta}}^{\top}\vec{\mathbf{r}}\right]_{j} = \sum_{i=0}^{N-1}2\frac{x_{ij} - \beta_{j}}{\beta_{3+j}^2} \left( 1 - \sum_{k=0,1,2} \frac{(x_{ik} - \beta_{k})^2}{\beta_{3+k}^2} \right) \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cvec%7B%5Cmathbf%7Br%7D%7D%5Cright%5D_%7Bj%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D2%5Cfrac%7Bx_%7Bij%7D+-+%5Cbeta_%7Bj%7D%7D%7B%5Cbeta_%7B3%2Bj%7D%5E2%7D+%5Cleft%28+1+-+%5Csum_%7Bk%3D0%2C1%2C2%7D+%5Cfrac%7B%28x_%7Bik%7D+-+%5Cbeta_%7Bk%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bk%7D%5E2%7D+%5Cright%29+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
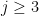
![\displaystyle \left[\mathbf{J}_{\bar{\beta}}^{\top}\vec{\mathbf{r}}\right]_{j} = \sum_{i=0}^{N-1}2\frac{(x_{i(j-3)} - \beta_{(j-3)})^2}{\beta_{j}^3} \left( 1 - \sum_{k=0,1,2} \frac{(x_{ik} - \beta_{k})^2}{\beta_{3+k}^2} \right) \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cmathbf%7BJ%7D_%7B%5Cbar%7B%5Cbeta%7D%7D%5E%7B%5Ctop%7D%5Cvec%7B%5Cmathbf%7Br%7D%7D%5Cright%5D_%7Bj%7D+%3D+%5Csum_%7Bi%3D0%7D%5E%7BN-1%7D2%5Cfrac%7B%28x_%7Bi%28j-3%29%7D+-+%5Cbeta_%7B%28j-3%29%7D%29%5E2%7D%7B%5Cbeta_%7Bj%7D%5E3%7D+%5Cleft%28+1+-+%5Csum_%7Bk%3D0%2C1%2C2%7D+%5Cfrac%7B%28x_%7Bik%7D+-+%5Cbeta_%7Bk%7D%29%5E2%7D%7B%5Cbeta_%7B3%2Bk%7D%5E2%7D+%5Cright%29+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
So all of the matrix entries we need to compute can be accumulated one observation at a time. We can store the observations, then at each iteration step in the Gauss-Newton algorithm run through these observations and use the formulas above to accumulate the matrix entries. Once we have done that, it is simple linear algebra to solve the matrix equation, find 

2. Putting it into code
Now let’s translate this into C++. We won’t try to engineer the code here, just outline a simple Arduino sketch that does the job.
To start, we will need to declare some arrays to hold 
//matrices for Gauss-Newton computations float JtJ[6][6]; float JtR[6]; float delta[6]; float beta[6]; //Array of observations int16_t* x; //malloc this to length 3*N in setup().
This amounts to 


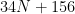
With those declared, let’s look at the calibrate() routine. It starts by setting up some general parameters — how small a eps), after how many iterations should we give up? (num_iterations), how big was the last change) — then enters the main loop. There is nothing subtle about this loop, just
- clear the matrices
- compute the calibration matrices
- find
- measure the size of
- adjust
Here is what that looks like in code.
void calibrate() {
int i;
float eps = 0.000000001;
int num_iterations = 20;
float change = 100.0;
while (--num_iterations >=0 && change > eps) {
//set all of the matrix entries to zero.
reset_calibration_matrices();
//use the samples and the current values of beta to compute
// the matrices JtJ and JtR
compute_calibration_matrices();
//solve the matrix equation JtJ*delta = JtR
find_delta();
//find the size of delta (look at log change in the coefficient parameters)
change = delta[0]*delta[0] + delta[1]*delta[1] + delta[2]*delta[2] + delta[3]*delta[3]/(beta[3]*beta[3]) + delta[4]*delta[4]/(beta[4]*beta[4]) + delta[5]*delta[5]/(beta[5]*beta[5]);
//adjust beta
for(i=0;i<6;++i) {
beta[i] -= delta[i];
}
}
}
But up to this is really just a template for an algorithm. As we’ve just been discussing, the real work of the algorithm all falls in to the routine compute_matrices(). Everything else is simple. In this implementation, we compute the matrices by scanning the samples and updating the matrix entries as required by Equations 1–5. Here is an implementation.
void compute_calibration_matrices() {
int i;
reset_calibration_matrices();
for(i=0;i<N;i++) {
update_calibration_matrices(x+3*i);
}
}
void update_calibration_matrices(const unsigned int* data) {
int j, k;
float dx, b;
float residual = 1.0;
float jacobian[6];
for(j=0;j<3;++j) {
b = beta[3+j];
dx = ((float)data[j])- beta[j];
residual -= pow(dx/b,2);
jacobian[j] = 2.0*dx/pow(b,2);
jacobian[3+j] = 2.0*dx*dx/pow(b,3);
}
for(j=0;j<6;++j) {
JtR[j] += jacobian[j]*residual;
for(k=0;k<6;++k) {
JtJ[j][k] += jacobian[j]*jacobian[k];
}
}
}
3. Wrap-up and what’s next
By being careful about computing only the matrices we need, we were able to reduce the memory cost of the Gauss-Newton algorithm significantly and produce an algorithm that is viable on an inexpensive microcontroller. But we still need to keep the samples around and make a full pass through the sample set with each iterative pass — as
In the next post we will see that even here we are storing too much. Thanks to the nature of our residual function, we will see that there are 25 statistics that we can compute in one pass through the observation set that contain all of the information we need to compute

Pingback: Implementing the Gauss-Newton Algorithm for Sphere Fitting (3 of 3) | Chionotech
Hey Ralph! Thanks for all the help, but is there a chance you could explain what each of your variables represent in lay mans terms, like beta etc. I was following you with mx, my, and mz and deltax deltay and deltaz, but now Im afraid Im lost. Thank you if you can help please!!!!